Introduction
At Loop, we're building an AI-native logistics data platform that unifies fragmented transportation and shipping data into a single source of truth. Our platform automates previously manual workflows across freight audit, parcel tracking, carrier payments, and cost allocation, processing millions of logistics events daily for our clients.
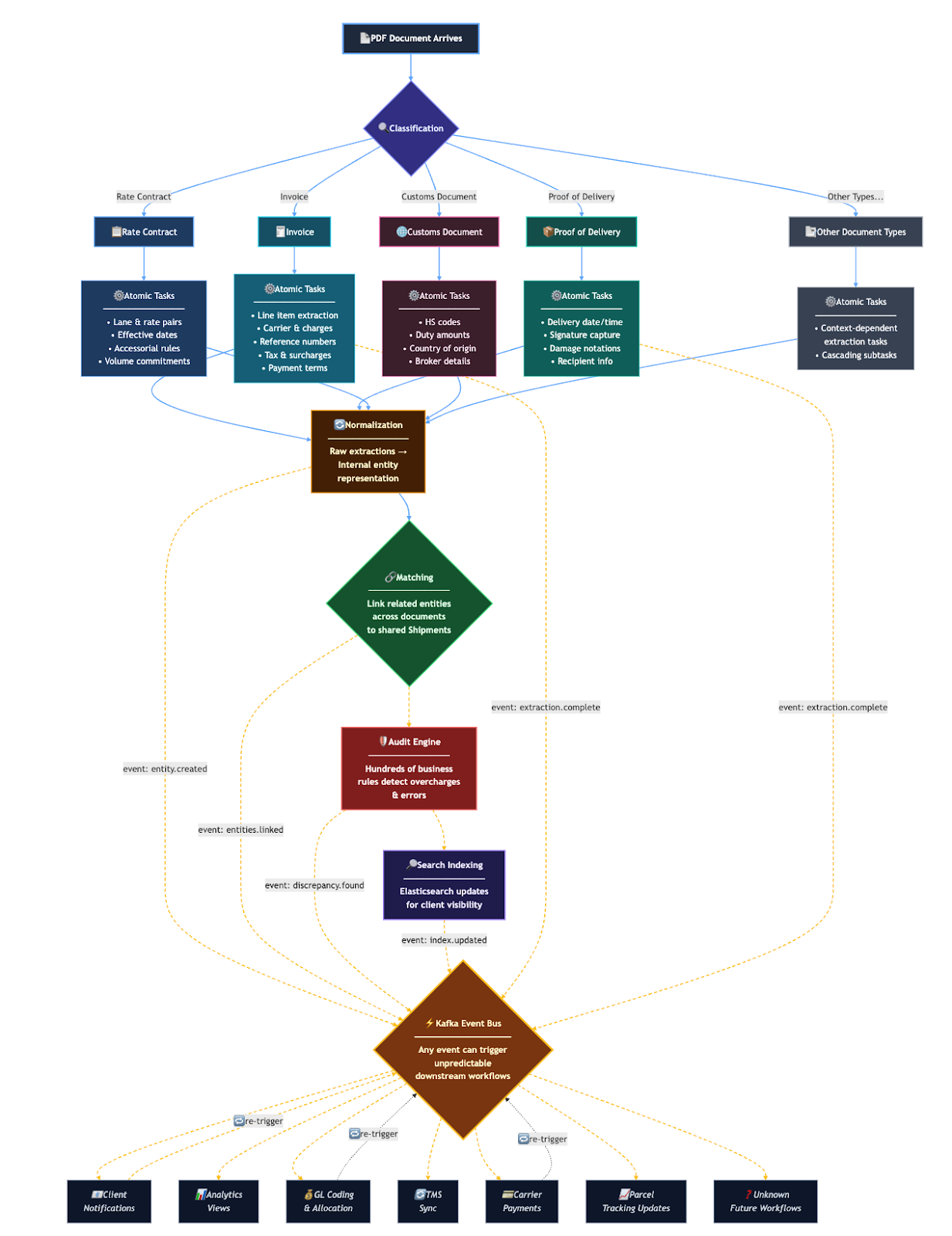
The complexity of our domain is staggering. For example, let's consider what happens when a single PDF arrives:
- Classification: We first need to determine what type of document the PDF file is. For example, it may be an Invoice, Proof of Delivery, Rate Contract, Customs Document, or many more.
- Atomic Tasks: Once we know what type of document it is, next we extract all of the details from the document using the Atomic Task System. These data points are extracted as requested by the many Domains throughout our backend, and may cascade depending on the datapoints that were extracted in previous tasks.
- Normalization: Once extraction has reached a point where we are confident all of the necessary data is extracted. We turn the raw extracted data into our own internal representation of entities
- Matching: This step links related entities that may have come into our system at different times. For example, a separate Bill of Lading PDF and Invoice PDF would be linked to a shared Shipment entity.
- Audit: We then apply hundreds of business rules to detect overcharges and errors on these shared entities.
- Search Indexing: Throughout these entity updates, we continuously update Elasticsearch indices for client visibility.
- Many more: On top of all this there may be many other steps not listed. These include sending notifications to clients, populating analytics views, categorizing charges to GL coding rules, syncing data to a client TMS, and more.
This is where event-driven architecture becomes essential. Rather than tightly coupling these systems with synchronous service calls or batch jobs, we model each business state change as an immutable event. These events flow through our platform, triggering specialized consumers that handle specific aspects of processing.
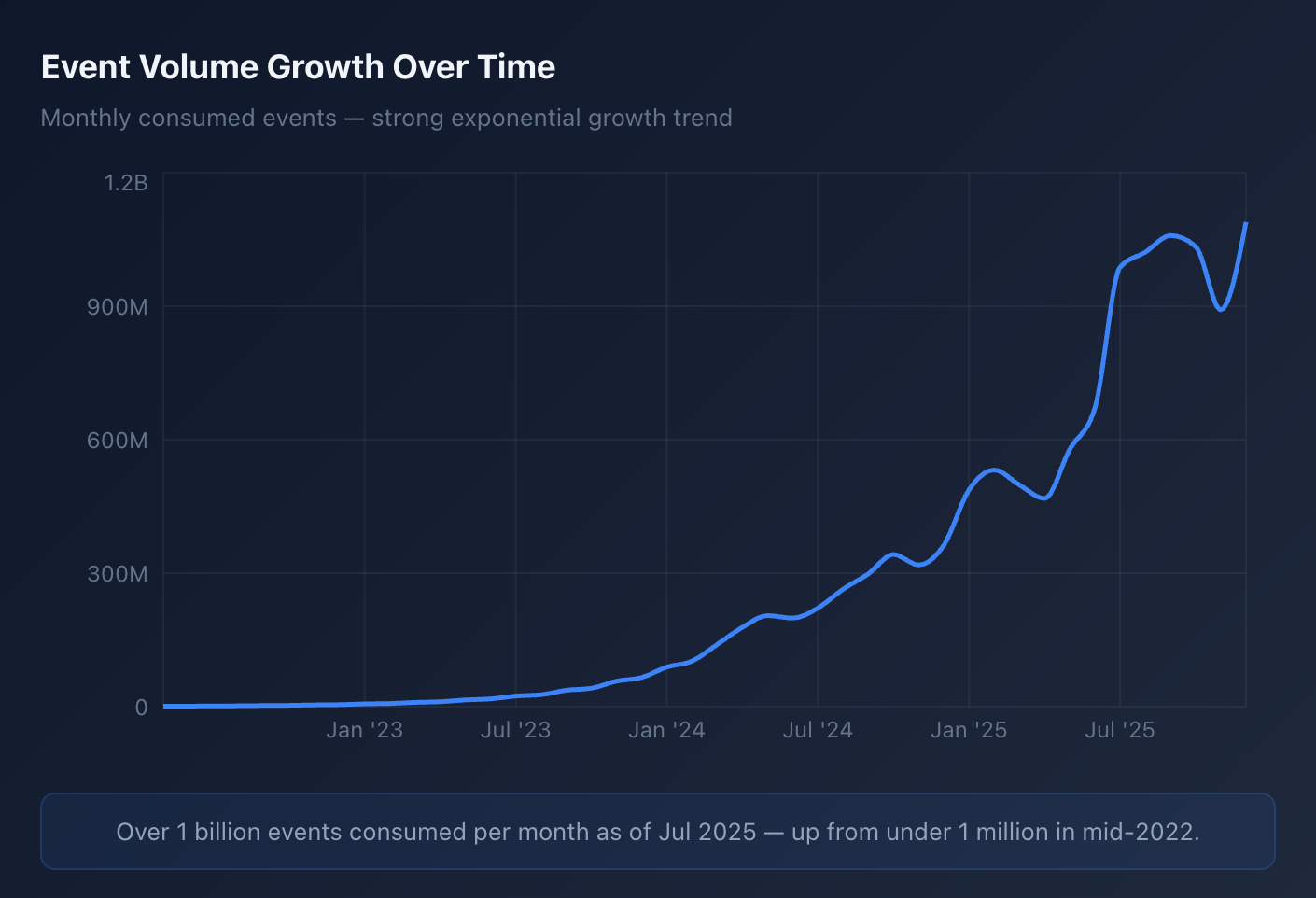
After all is said and done, a single PDF might generate 50+ discrete processing tasks across our system. This manifests as nearly 100 million of Kafka events delivered to consumers every day; all must be processed reliably, in order, with strong consistency guarantees.
The rest of this post explores how we built and scaled this event-driven architecture, and the challenges we faced along the way.
Event driven design at Loop
Since these events are critical in ensuring work is completed on all entities that enter our system, our event system has a two guarantees we must uphold:
- At least once delivery.
- Entity mutations must create the expected events.
- Events must be delivered in order per event type. For example, if a consumer is listening for foo_entity_revised events, we don’t want a deletion event arriving before a creation event.
Durable events
To ensure these requirements, we built the Durable Event system. This system is built on three core components: a transactional outbox in our backend Postgres database, a dedicated service writing the outbox to Kafka, and event consumer handlers.

This system was first created in May of 2022 and has been a stable foundation of our backend ever since. Event volume has grown drastically, today we handle over 3 billion events per month.
How it works
When business logic needs to publish an event, we write it to a durable_event_outbox database table in the same transaction as the business data change:
// pseudocode for brevity
async auditInvoice(ctx: CtxDto, invoiceQid: Qid) {
// (actual business logic omitted)
return this.prisma.$transaction([
// Update business state
this.prisma.payableInvoice.update({
where: { qid: invoiceQid },
data: { status: InvoiceStatus.AUDITED }
}),
// Write event to outbox (atomically)
this.durableEventService.publishToOutboxOp(
ctx,
InvoiceAuditedEventPayload.from({ invoiceQid }),
InvoiceAuditedEventTopicConfig
)
]);
}
This transactional approach ensures either both the state change and event commit, or neither does. No inconsistent states.
Once written, a background poller continuously reads from the outbox and publishes events to Kafka topics (named durable_event.<event_type>). All events include a partition key typically using the ID of the entity being mutated to ensure ordering within that entity. For example, all events with the same invoice identifier are sent to the same Kafka topic partition so they can be processed sequentially.
On the consuming side, we have 300+ consumers that subscribe to specific Kafka topics and perform business logic. We use simplified SingleEventConsumer and BatchEventConsumer base classes to simplify the interface for developers:
export class InvoiceSearchIndexerConsumer extends SingleEventConsumer<InvoiceAuditedPayload> {
protected readonly eventTopicConfigs = [InvoiceAuditedEventTopicConfig];
protected readonly consumerKey =
DurableEventConsumerKey.INVOICE_SEARCH_INDEXER;
async handleEvent(
ctx: CtxDto,
event: DurableEventDto<InvoiceAuditedPayload>,
): Promise<void> {
const invoice = await this.invoiceLoader
.byQid(ctx)
.load(event.payload.invoiceQid);
await this.elasticsearchService.indexInvoice(invoice);
}
}
Each EventConsumer type gets its own Kafka consumer group and can be set up to consume one or more topics. The framework also handles retries, timeouts, dead-letter queues, observability, and alerting automatically.
Scaling bottlenecks
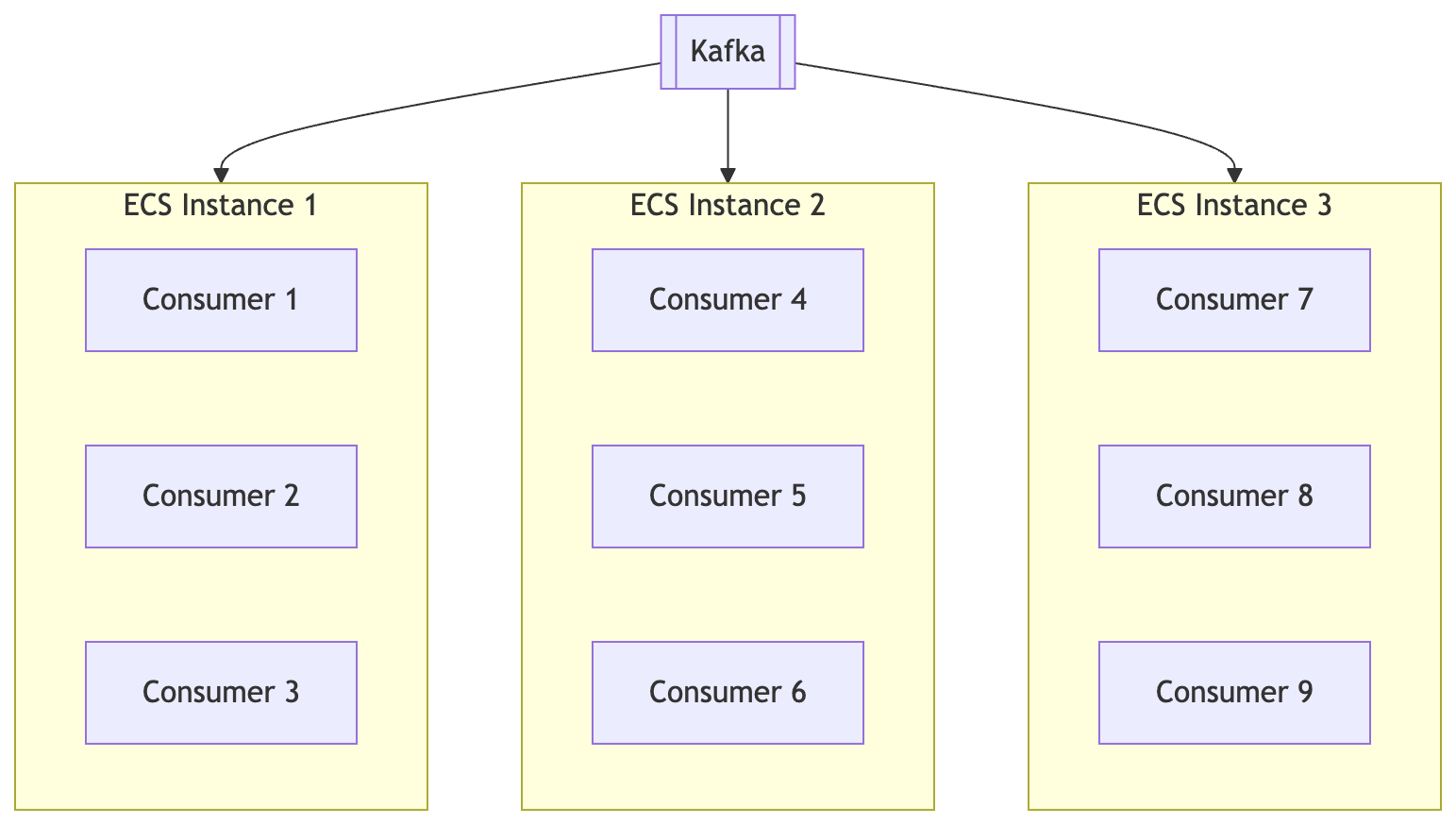
As our client base grew, we hit limitations in how we deployed consumers. Initially, we ran consumers statically across a fixed number of Node.js instances, manually assigning them based on team ownership:
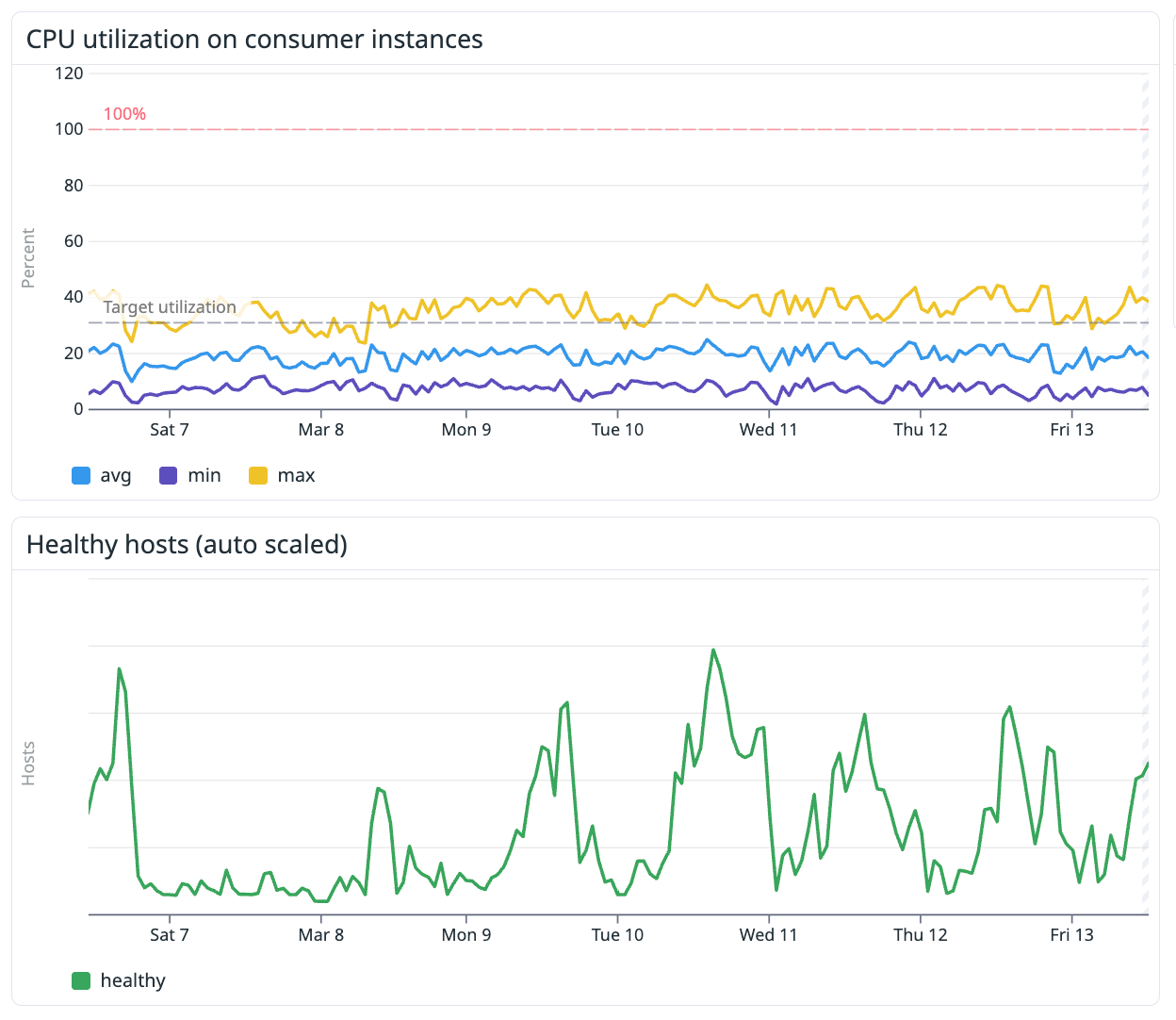
This approach had a fundamental problem: consumer workloads are imbalanced. Consumer workloads vary dramatically. When we grouped consumers by team ownership, some boxes ran hot (90% CPU) while others sat mostly idle (10% CPU). This wasted resources and created processing delays during peak hours.
Inefficient rebalancing
In order to account for imbalance load on our consumer instances, we got a bit hacky and built a script that queried Datadog for CPU metrics and redistributed consumers using a bin-packing algorithm. It ran weekly or when someone noticed performance issues.
This had several problems, especially if we want to add more ECS instances to handle scaling:
- Slow: Rebalancing took 60+ minutes; deploy new tasks to ECS, run rebalance script with new instances registered, review changes, deploy.
- Reactive: We only rebalanced when someone noticed high CPU or consumer lag alerts. Traffic spikes required manual intervention.
High AWS costs
This rebalancing script approach worked okay for a while, but as we continued to scale reactively, we eventually got to a point where we had 40+ ECS consumer instances running constantly. These boxes ran 24/7 to handle peak load, but during off-peak times (nights, weekends) left most capacity idle. This resulted in thousands of dollars wasted on unused ECS compute capacity.
The consumer proxy solution
To solve the problems outlined above, we introduced the consumer proxy.
Architecture overview
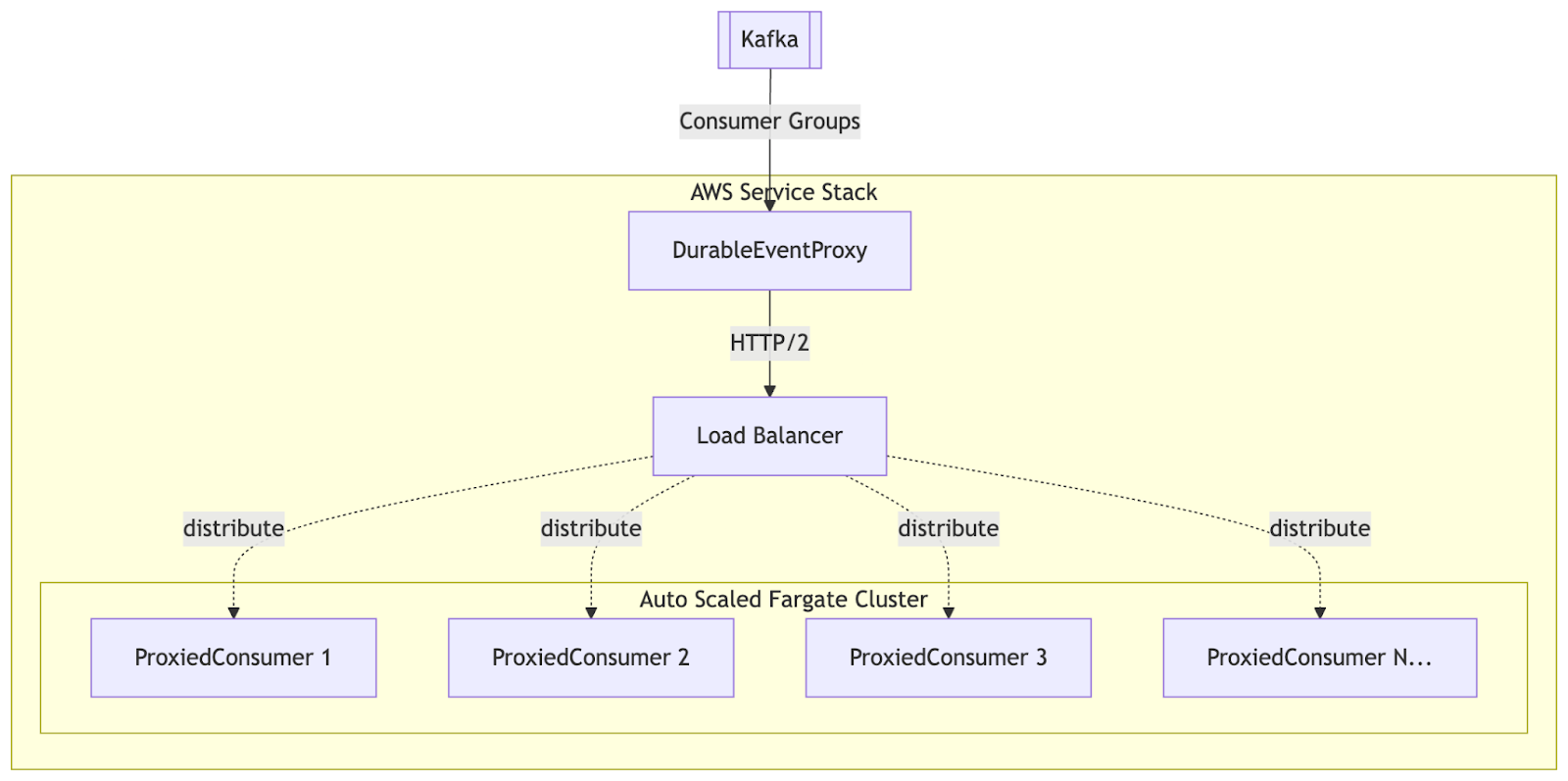
The proxy runs as a standalone service written in Go. This service handles the Kafka consumer layer much more efficiently than we were doing previously on each of our consumer instances.
This server handled the following:
- Polling Kafka for events across all consumer groups. The library we use franz-go batches requests within a consumer group to avoid unnecessary round trips to the Kafka server.
- When sending to the consumer, events are batched per topic/partition for maximum throughput
- Requests are sent to the consumer backend via an AWS load balancer and HTTP/2 requests
- The proxy layer commits offsets based on what the backend successfully processed
How it works
Auto scaled consumer instances
The consumer handler service runs as a pool of ECS Fargate tasks behind an AWS Application Load Balancer. Each consumer instance registers all 300+ consumer handler classes and can handle any event type. When the proxy forwards a batch, the load balancer routes it to any available handler task, which looks up the appropriate consumer by consumerGroupId and processes the events.
The key improvement: the service autoscales based on aggregate demand across all consumers. Instead of manually rebalancing consumers across boxes, ECS automatically adds or removes tasks based on CPU usage. The proxy handles all Kafka complexity (consumer groups, offset management, rebalancing), while the backend focuses purely on event processing.
Dynamic consumer registration
Every 30 seconds, the proxy asks the backend: "What consumer groups should I run?"
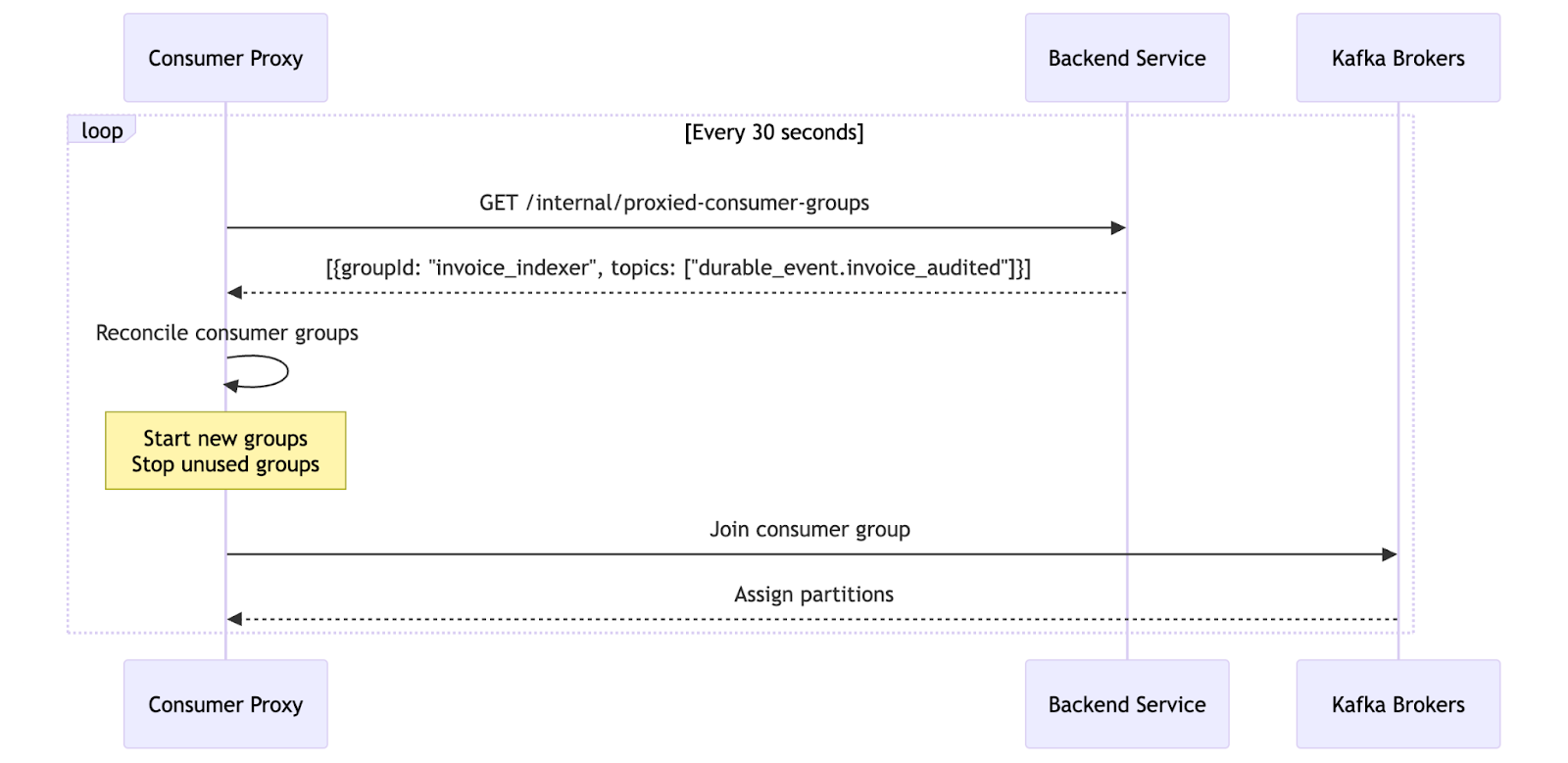
The backend returns a list of consumer groups it wants active. The proxy reconciles this with its running consumer groups; starting new ones, stopping old ones. No static configuration is needed.
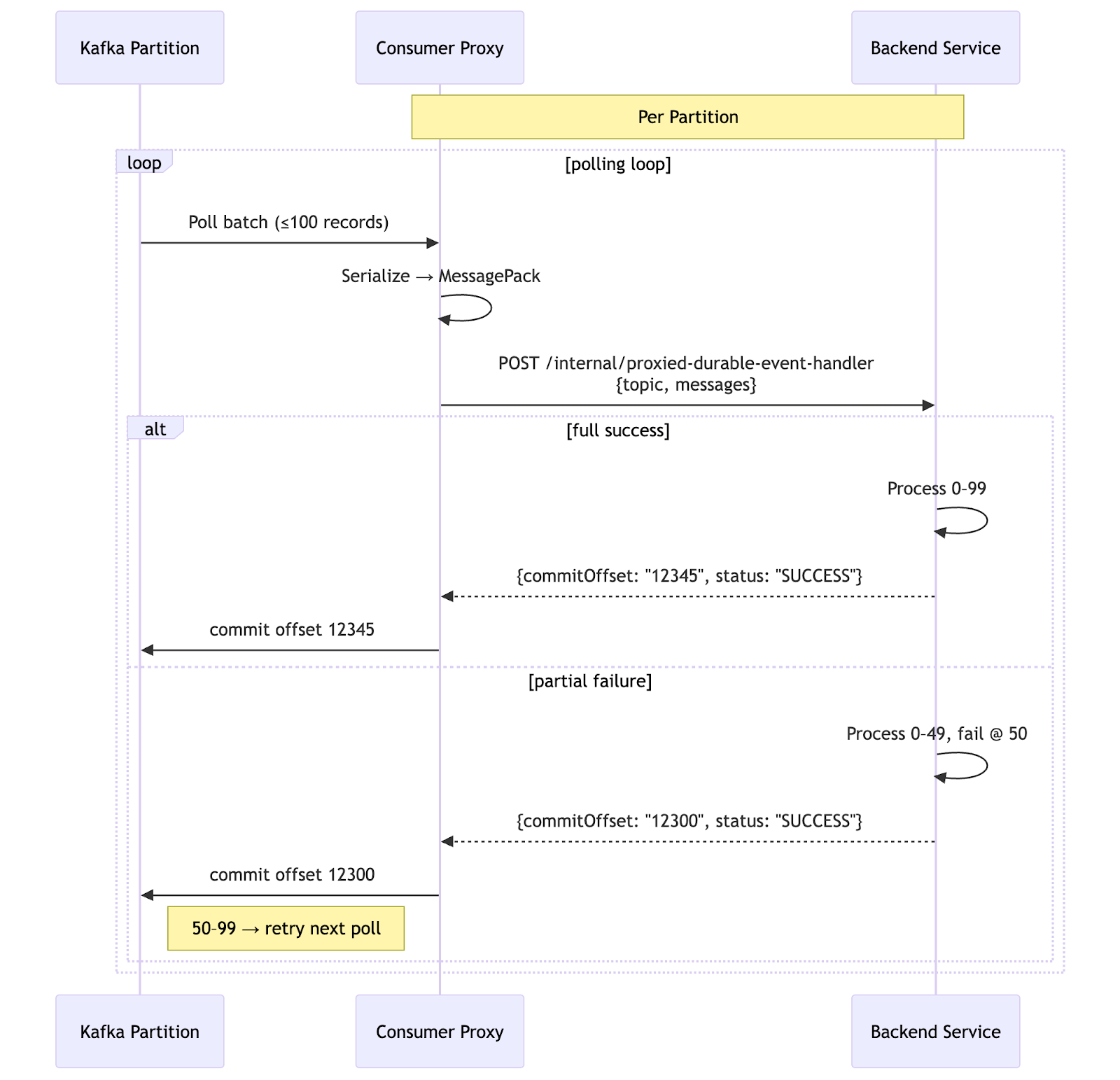
Per partition processing
For each consumer group, the proxy runs an independent consumer loop and processes each topic/partition separately. This enables peak throughput and parallelization while ensuring that events within each partition are sent and handled in order.
Why Golang for the proxy?
NodeJS wasn’t working
Initially we had planned to write this service as NodeJS so it was aligned with the rest of our backend, but quickly ran into issues with Kafka library limitations.
There really are only two main libraries in the Nodejs ecosystem, each has its own limitations:
- KafkaJS: This library has the per partition isolation we wanted to enable high throughput, but we quickly realized the overhead of the library was too much. We would need 10+ proxy instances just to handle our volume of consumers. This would negate the cost benefits of auto scalable handlers.
- node-rdkafka: This library is solid but requires bindings to the underlying rdkafka C library. This makes it more efficient than KafkaJS, but still struggles to handle the required throughput. It also does not have the APIs we needed to easily manage per partition concurrency in a clean way.
Go worked better than expected
After a failed attempt at NodeJS, we pivoted to use Golang because it was a language a few of us were familiar with from previous work experience, and we knew it had much greater performance capabilities when compared to NodeJs.
Go shined for this use case for a few reasons:
- Performance: Go's concurrency primitives (goroutines, channels) are perfect for handling thousands of concurrent Kafka partitions. It also is able to utilize all CPUs instead of being bound to a single threaded event loop like NodeJs.
- franz-go: This Kafka library is thoughtfully designed and is able to cleanly handle our per partition consumer pattern. The author even provides a clean example for how this can be done effectively.
This Go server is currently able to handle all 330+ of our consumer groups on a single 4CPU 8GB memory ECS task while barely breaking a sweat. This will allow us to continue to scale this system to handle much higher volume.
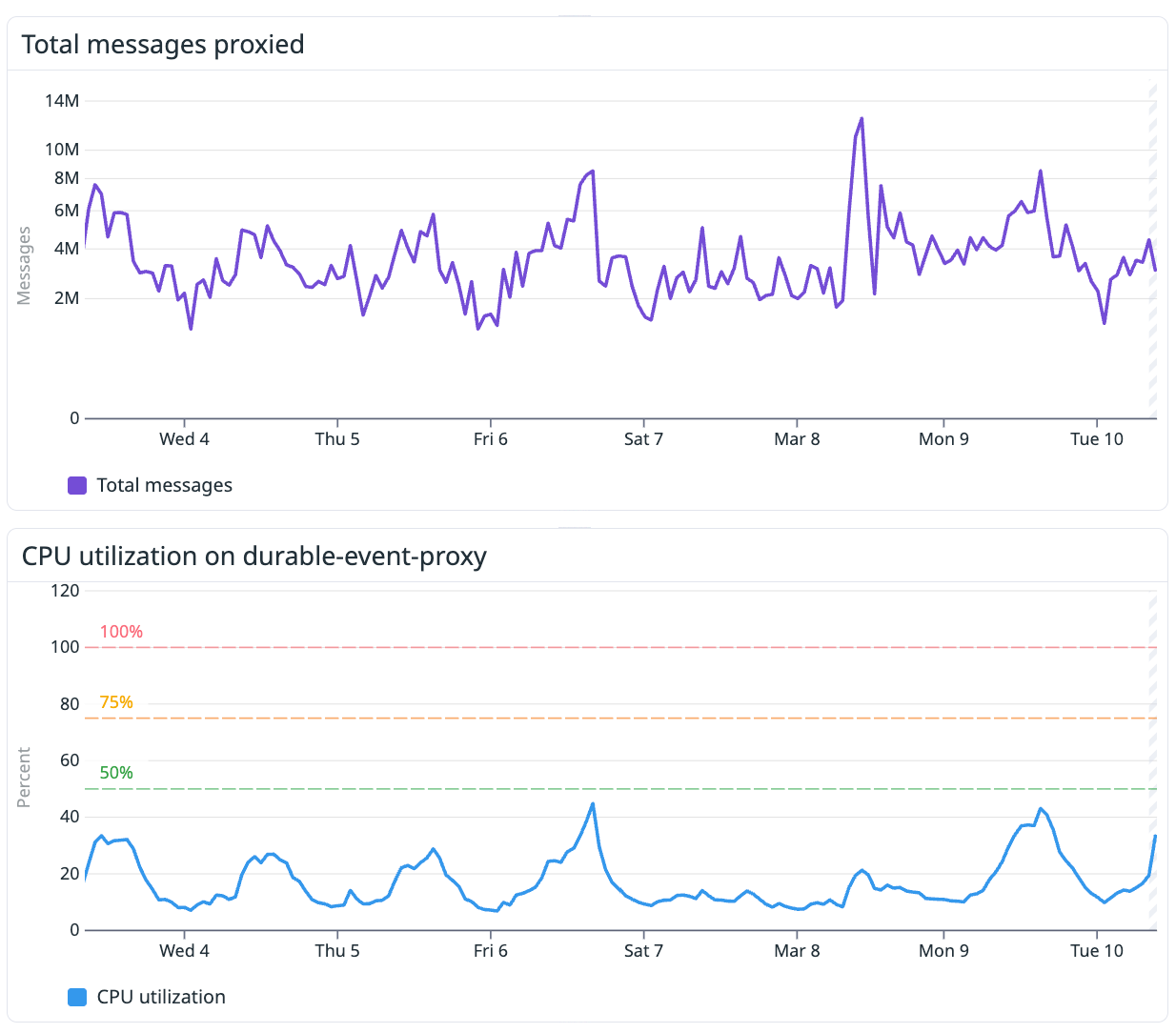
Operational results
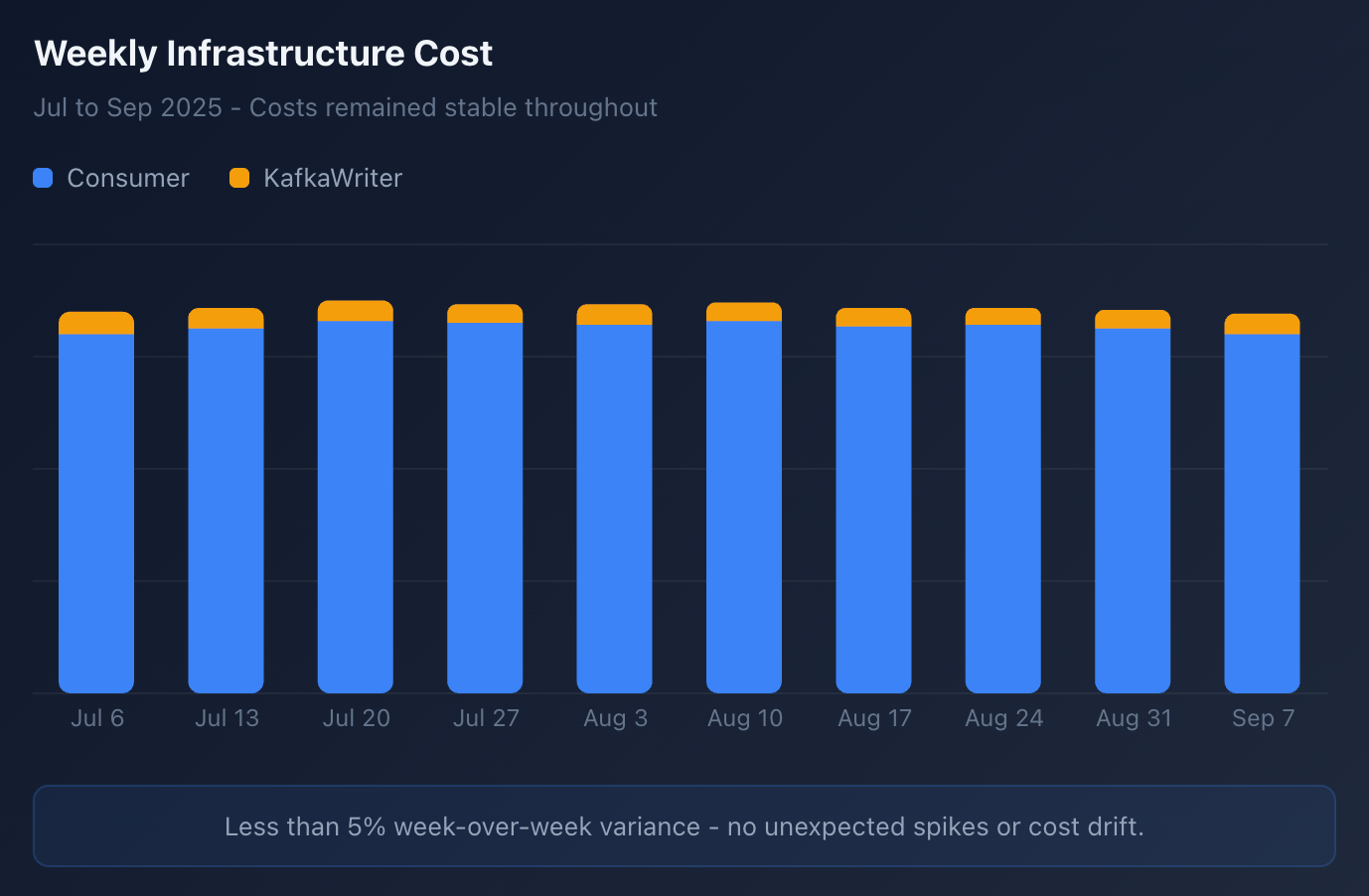
Cost savings
We’ve been running this proxied durable event consumer since the beginning of October, and it has cut our AWS costs by about 50%.
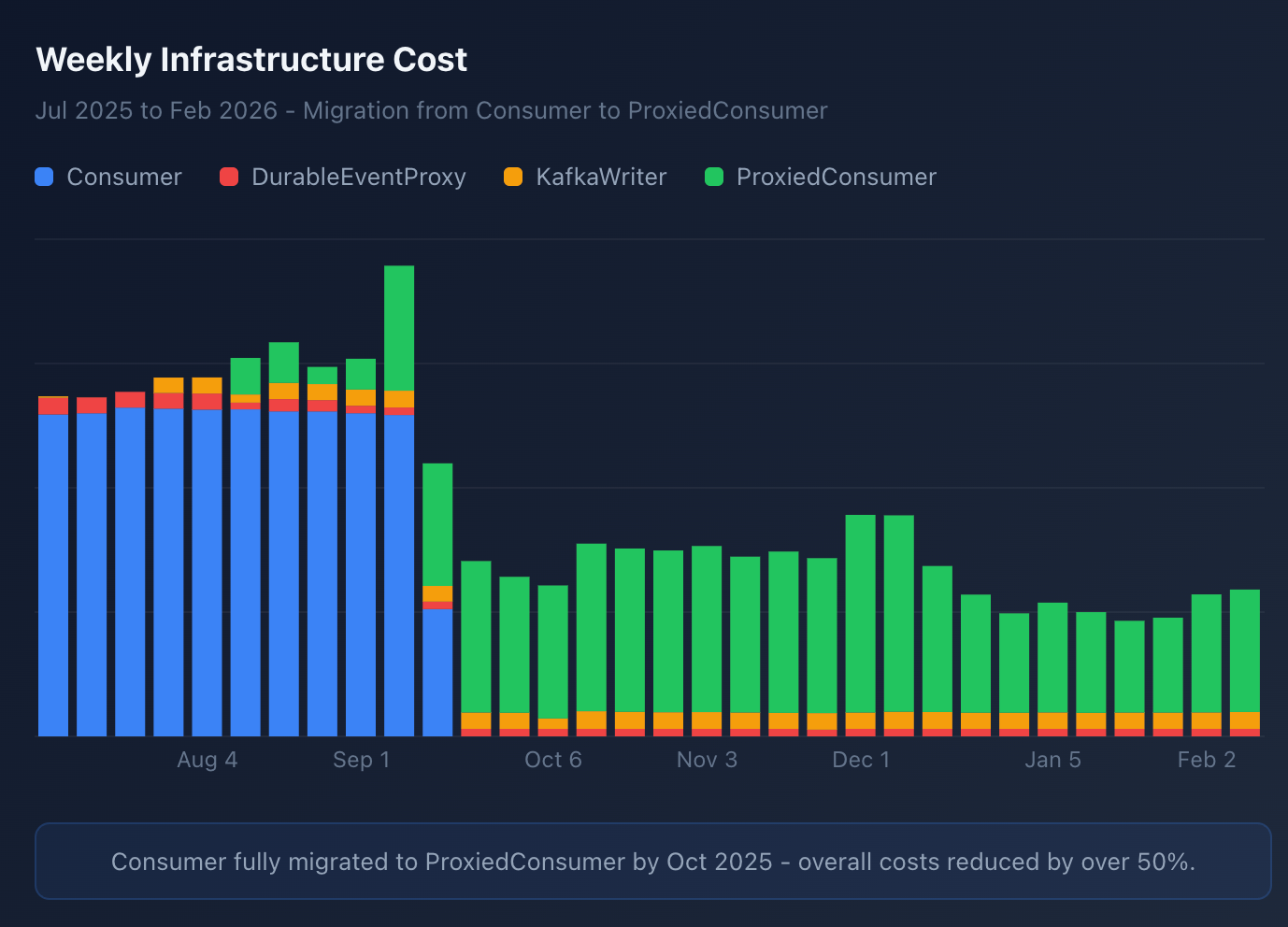
This cost savings is primarily driven by the auto scalability. This has been working great and we are able to reliably handle peak volumes, while also scaling down during off hours and weekends when volume is slow.